Engine Configuration¶
Engine はSQLAlchemyアプリケーションの出発点です。これは実際のデータベースとその DBAPI の”ホームベース”であり、接続プールと Dialect を通してSQLAlchemyアプリケーションに提供されます。 Dialect は特定の種類のデータベース/DBAPIの組み合わせとの対話方法を記述します。
一般的な構造は次のように説明できます。
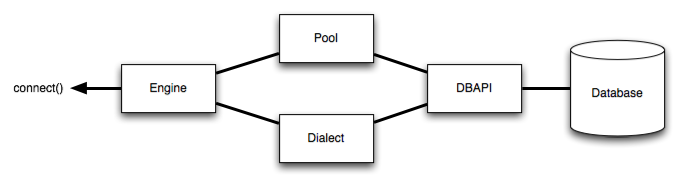
上記の場合、 Engine は Dialect と Pool の両方を参照します。これらは共にDBAPIのモジュール関数とデータベースの振る舞いを解釈します。
エンジンを作成するには、 create_engine() を1回呼び出すだけです:
from sqlalchemy import create_engine
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost:5432/mydatabase")上のエンジンは、PostgreSQL用に調整された Dialect オブジェクトと、接続要求が最初に受信されたときに localhost:5432 でaDBAPI接続を確立する Pool オブジェクトを作成します。 Engine とその基礎となる Pool は、 Engine.connect() または Engine.begin() メソッドが呼び出されるまで、最初の実際のDBAPI接続を確立 しない ことに注意してください。これらのメソッドのどちらも、ORM Session オブジェクトのような他のSQLAlchemy Engine 依存オブジェクトが最初にデータベース接続を必要とするときに呼び出されることもあります。このように、 Engine と Pool は 遅延初期化 動作をすると言えます。
Engine が作成されると、データベースとの対話に直接使用することも、 Session オブジェクトに渡してORMを操作することもできます。このセクションでは、 Engine の設定の詳細について説明します。次のセクション Working with Engines and Connections では、 Engine など(通常はORM以外のアプリケーション用)の使用APIについて詳しく説明します。
Supported Databases¶
SQLAlchemyには、さまざまなバックエンドのための多くの Dialect 実装が含まれています。最も一般的なデータベースのダイアレクトはSQLAlchemyに含まれています。その他のいくつかは、別のダイアレクトを追加でインストールする必要があります。
利用可能な様々なバックエンドについては Dialects を参照してください。
Database URLs¶
create_engine() 関数は、URLに基づいて Engine オブジェクトを生成します。URLのフォーマットは一般的に RFC-1738 に従いますが、ダッシュやピリオドではなくアンダースコアが”scheme”部分で受け入れられるなど、いくつかの例外があります。URLには通常、ユーザ名、パスワード、ホスト名、データベース名のフィールド、および追加設定のためのオプションのキーワード引数が含まれます。ファイルパスが受け入れられる場合もあれば、”host”と”database”の部分が”data source name”に置き換えられる場合もあります。データベースURLの一般的な形式は次のとおりです:
dialect+driver://username:password@host:port/databaseダイアレクト名には、SQLAlchemyダイアレクトの識別名が含まれます。たとえば、 sqlite 、 mysql 、 postgresql 、 oracle 、 mssql などの名前です。drivernameは、データベースへの接続に使用されるDBAPIの名前で、すべて小文字を使用します。指定しない場合、使用可能であれば「デフォルト」のDBAPIがインポートされます。このデフォルトは、通常、そのバックエンドで使用可能な最も広く知られているドライバです。
Escaping Special Characters such as @ signs in Passwords¶
完全な形式のURL文字列を構築して create_engine() に渡す場合、 ユーザやパスワードで使用される可能性のある特殊文字は、正しく解析するためにURLエンコードする必要があります。 。 これには@記号 が含まれます。
以下は、パスワード kx@jj5/g を含むURLの例です。ここで、 at 記号とスラッシュ文字は、それぞれ %40 と %2F と表されます:
postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdb上記のパスワードのエンコーディングは urllib.parse を使って生成できます。:
>>> import urllib.parse
>>> urllib.parse.quote_plus("kx@jj5/g")
'kx%40jj5%2Fg'URLは文字列として create_engine() に渡すことができます:
from sqlalchemy import create_engine
engine = create_engine("postgresql+pg8000://dbuser:kx%40jj5%2Fg@pghost10/appdb")完全なURL文字列を作成するために特殊文字をエスケープする代わりに、 create_engine() に渡されるオブジェクトを URL オブジェクトのインスタンスにすることもできます。これは構文解析フェーズをバイパスし、エスケープされていない文字列を直接受け入れることができます。例については次のセクションを参照してください。
Changed in version 1.4:
ホスト名とデータベース名における @ 記号のサポートが修正されました。この修正の副作用として、パスワードにおける @ 記号はエスケープされなければなりません。
Creating URLs Programmatically¶
create_engine() に渡される値は、普通の文字列ではなく URL のインスタンスである可能性があります。これは、使用される文字列解析の必要性を回避するので、エスケープされたURL文字列を提供する必要はありません。
URL オブジェクトは、 URL.create() コンストラクタメソッドを使用して作成され、すべてのフィールドを個別に渡します。パスワード内の文字などの特殊文字は、変更せずに渡すことができます:
from sqlalchemy import URL
url_object = URL.create(
"postgresql+pg8000",
username="dbuser",
password="kx@jj5/g", # plain (unescaped) text
host="pghost10",
database="appdb",
)構築された URL オブジェクトは、文字列引数の代わりに create_engine() に直接渡すことができます:
from sqlalchemy import create_engine
engine = create_engine(url_object)Backend-Specific URLs¶
一般的な接続スタイルの例を以下に示します。含まれているすべての方言に関する詳細情報の完全な索引と、サードパーティの方言へのリンクについては、 Dialects を参照してください。
PostgreSQL¶
PostgreSQLダイアレクトはデフォルトのDBAPIとしてpsycopg2を使用します。その他のPostgreSQL DBAPIにはpg8000とasyncpgがあります:
# default
engine = create_engine("postgresql://scott:tiger@localhost/mydatabase")
# psycopg2
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/mydatabase")
# pg8000
engine = create_engine("postgresql+pg8000://scott:tiger@localhost/mydatabase")PostgreSQLへの接続に関するさらなる注意は PostgreSQL にあります。
MySQL¶
MySQLダイアレクトでは、mysqlclientをデフォルトのDBAPIとして使用します。PyMySQLなど、他のMySQL DBAPIも使用できます:
# default
engine = create_engine("mysql://scott:tiger@localhost/foo")
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine("mysql+mysqldb://scott:tiger@localhost/foo")
# PyMySQL
engine = create_engine("mysql+pymysql://scott:tiger@localhost/foo")MySQLへの接続に関するさらなる注意は MySQL and MariaDB にあります。
Oracle¶
Oracleダイアレクトでは、デフォルトのDBAPIとしてcx_oracleが使用されます:
engine = create_engine("oracle://scott:tiger@127.0.0.1:1521/sidname")
engine = create_engine("oracle+cx_oracle://scott:tiger@tnsname")Oracleへの接続に関するさらなる注意は Oracle にあります。
Microsoft SQL Server¶
SQL Serverダイアレクトでは、デフォルトのDBAPIとしてpyodbcを使用します。pymssqlも使用できます:
# pyodbc
engine = create_engine("mssql+pyodbc://scott:tiger@mydsn")
# pymssql
engine = create_engine("mssql+pymssql://scott:tiger@hostname:port/dbname")SQL Serverへの接続に関するその他の注意事項は Microsoft SQL Server にあります。
SQLite¶
SQLiteはファイルベースのデータベースに接続します。デフォルトではPythonの組み込みモジュール sqlite3 を使用します。
SQLiteはローカルファイルに接続するので、URLの形式は少し異なります。URLの”ファイル”部分はデータベースのファイル名です。相対ファイルパスの場合、3つのスラッシュが必要です:
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine("sqlite:///foo.db")絶対ファイルパスの場合、3つのスラッシュの後に絶対パスが続きます:
# Unix/Mac - 4 initial slashes in total
engine = create_engine("sqlite:////absolute/path/to/foo.db")
# Windows
engine = create_engine("sqlite:///C:\\path\\to\\foo.db")
# Windows alternative using raw string
engine = create_engine(r"sqlite:///C:\path\to\foo.db")SQLiteの :memory: データベースを使用するには、空のURLを指定します:
engine = create_engine("sqlite://")SQLiteへの接続に関する注意は SQLite にあります。
Others¶
Dialects を参照してください。これはすべての追加のダイアレクトドキュメントのトップレベルページです。
Engine Creation API¶
| Object Name | Description |
|---|---|
create_engine(url, **kwargs) |
Create a new |
create_mock_engine(url, executor, **kw) |
Create a “mock” engine used for echoing DDL. |
create_pool_from_url(url, **kwargs) |
Create a pool instance from the given url. |
engine_from_config(configuration[, prefix], **kwargs) |
Create a new Engine instance using a configuration dictionary. |
make_url(name_or_url) |
Given a string, produce a new URL instance. |
Represent the components of a URL used to connect to a database. |
- function sqlalchemy.create_engine(url: str | _url.URL, **kwargs: Any) Engine¶
Create a new
Engineinstance.The standard calling form is to send the URL as the first positional argument, usually a string that indicates database dialect and connection arguments:
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/test")
Note
Please review Database URLs for general guidelines in composing URL strings. In particular, special characters, such as those often part of passwords, must be URL encoded to be properly parsed.
Additional keyword arguments may then follow it which establish various options on the resulting
Engineand its underlyingDialectandPoolconstructs:engine = create_engine("mysql+mysqldb://scott:tiger@hostname/dbname", pool_recycle=3600, echo=True)
The string form of the URL is
dialect[+driver]://user:password@host/dbname[?key=value..], wheredialectis a database name such asmysql,oracle,postgresql, etc., anddriverthe name of a DBAPI, such aspsycopg2,pyodbc,cx_oracle, etc. Alternatively, the URL can be an instance ofURL.**kwargstakes a wide variety of options which are routed towards their appropriate components. Arguments may be specific to theEngine, the underlyingDialect, as well as thePool. Specific dialects also accept keyword arguments that are unique to that dialect. Here, we describe the parameters that are common to mostcreate_engine()usage.Once established, the newly resulting
Enginewill request a connection from the underlyingPoolonceEngine.connect()is called, or a method which depends on it such asEngine.execute()is invoked. ThePoolin turn will establish the first actual DBAPI connection when this request is received. Thecreate_engine()call itself does not establish any actual DBAPI connections directly.- Parameters:
connect_args¶ – a dictionary of options which will be passed directly to the DBAPI’s
connect()method as additional keyword arguments. See the example at Custom DBAPI connect() arguments / on-connect routines.creator¶ –
a callable which returns a DBAPI connection. This creation function will be passed to the underlying connection pool and will be used to create all new database connections. Usage of this function causes connection parameters specified in the URL argument to be bypassed.
This hook is not as flexible as the newer
DialectEvents.do_connect()hook which allows complete control over how a connection is made to the database, given the full set of URL arguments and state beforehand.See also
DialectEvents.do_connect()- event hook that allows full control over DBAPI connection mechanics.echo=False¶ –
if True, the Engine will log all statements as well as a
repr()of their parameter lists to the default log handler, which defaults tosys.stdoutfor output. If set to the string"debug", result rows will be printed to the standard output as well. Theechoattribute ofEnginecan be modified at any time to turn logging on and off; direct control of logging is also available using the standard Pythonloggingmodule.See also
Configuring Logging - further detail on how to configure logging.
echo_pool=False¶ –
if True, the connection pool will log informational output such as when connections are invalidated as well as when connections are recycled to the default log handler, which defaults to
sys.stdoutfor output. If set to the string"debug", the logging will include pool checkouts and checkins. Direct control of logging is also available using the standard Pythonloggingmodule.See also
Configuring Logging - further detail on how to configure logging.
empty_in_strategy¶ –
No longer used; SQLAlchemy now uses “empty set” behavior for IN in all cases.
Deprecated since version 1.4: The
create_engine.empty_in_strategykeyword is deprecated, and no longer has any effect. All IN expressions are now rendered using the “expanding parameter” strategy which renders a set of boundexpressions, or an “empty set” SELECT, at statement executiontime.enable_from_linting¶ –
defaults to True. Will emit a warning if a given SELECT statement is found to have un-linked FROM elements which would cause a cartesian product.
New in version 1.4.
execution_options¶ – Dictionary execution options which will be applied to all connections. See
Connection.execution_options()future¶ –
Use the 2.0 style
EngineandConnectionAPI.As of SQLAlchemy 2.0, this parameter is present for backwards compatibility only and must remain at its default value of
True.The
create_engine.futureparameter will be deprecated in a subsequent 2.x release and eventually removed.New in version 1.4.
Changed in version 2.0: All
Engineobjects are “future” style engines and there is no longer afuture=Falsemode of operation.hide_parameters¶ –
Boolean, when set to True, SQL statement parameters will not be displayed in INFO logging nor will they be formatted into the string representation of
StatementErrorobjects.New in version 1.3.8.
See also
Configuring Logging - further detail on how to configure logging.
implicit_returning=True¶ – Legacy parameter that may only be set to True. In SQLAlchemy 2.0, this parameter does nothing. In order to disable “implicit returning” for statements invoked by the ORM, configure this on a per-table basis using the
Table.implicit_returningparameter.insertmanyvalues_page_size¶ –
number of rows to format into an INSERT statement when the statement uses “insertmanyvalues” mode, which is a paged form of bulk insert that is used for many backends when using executemany execution typically in conjunction with RETURNING. Defaults to 1000, but may also be subject to dialect-specific limiting factors which may override this value on a per-statement basis.
New in version 2.0.
isolation_level¶ –
optional string name of an isolation level which will be set on all new connections unconditionally. Isolation levels are typically some subset of the string names
"SERIALIZABLE","REPEATABLE READ","READ COMMITTED","READ UNCOMMITTED"and"AUTOCOMMIT"based on backend.The
create_engine.isolation_levelparameter is in contrast to theConnection.execution_options.isolation_levelexecution option, which may be set on an individualConnection, as well as the same parameter passed toEngine.execution_options(), where it may be used to create multiple engines with different isolation levels that share a common connection pool and dialect.Changed in version 2.0: The
create_engine.isolation_levelparameter has been generalized to work on all dialects which support the concept of isolation level, and is provided as a more succinct, up front configuration switch in contrast to the execution option which is more of an ad-hoc programmatic option.json_deserializer¶ –
for dialects that support the
JSONdatatype, this is a Python callable that will convert a JSON string to a Python object. By default, the Pythonjson.loadsfunction is used.Changed in version 1.3.7: The SQLite dialect renamed this from
_json_deserializer.json_serializer¶ –
for dialects that support the
JSONdatatype, this is a Python callable that will render a given object as JSON. By default, the Pythonjson.dumpsfunction is used.Changed in version 1.3.7: The SQLite dialect renamed this from
_json_serializer.label_length=None¶ –
optional integer value which limits the size of dynamically generated column labels to that many characters. If less than 6, labels are generated as “_(counter)”. If
None, the value ofdialect.max_identifier_length, which may be affected via thecreate_engine.max_identifier_lengthparameter, is used instead. The value ofcreate_engine.label_lengthmay not be larger than that ofcreate_engine.max_identfier_length.See also
logging_name¶ –
String identifier which will be used within the “name” field of logging records generated within the “sqlalchemy.engine” logger. Defaults to a hexstring of the object’s id.
See also
Configuring Logging - further detail on how to configure logging.
max_identifier_length¶ –
integer; override the max_identifier_length determined by the dialect. if
Noneor zero, has no effect. This is the database’s configured maximum number of characters that may be used in a SQL identifier such as a table name, column name, or label name. All dialects determine this value automatically, however in the case of a new database version for which this value has changed but SQLAlchemy’s dialect has not been adjusted, the value may be passed here.New in version 1.3.9.
See also
max_overflow=10¶ – the number of connections to allow in connection pool “overflow”, that is connections that can be opened above and beyond the pool_size setting, which defaults to five. this is only used with
QueuePool.module=None¶ – reference to a Python module object (the module itself, not its string name). Specifies an alternate DBAPI module to be used by the engine’s dialect. Each sub-dialect references a specific DBAPI which will be imported before first connect. This parameter causes the import to be bypassed, and the given module to be used instead. Can be used for testing of DBAPIs as well as to inject “mock” DBAPI implementations into the
Engine.paramstyle=None¶ – The paramstyle to use when rendering bound parameters. This style defaults to the one recommended by the DBAPI itself, which is retrieved from the
.paramstyleattribute of the DBAPI. However, most DBAPIs accept more than one paramstyle, and in particular it may be desirable to change a “named” paramstyle into a “positional” one, or vice versa. When this attribute is passed, it should be one of the values"qmark","numeric","named","format"or"pyformat", and should correspond to a parameter style known to be supported by the DBAPI in use.pool=None¶ – an already-constructed instance of
Pool, such as aQueuePoolinstance. If non-None, this pool will be used directly as the underlying connection pool for the engine, bypassing whatever connection parameters are present in the URL argument. For information on constructing connection pools manually, see Connection Pooling.poolclass=None¶ – a
Poolsubclass, which will be used to create a connection pool instance using the connection parameters given in the URL. Note this differs frompoolin that you don’t actually instantiate the pool in this case, you just indicate what type of pool to be used.pool_logging_name¶ –
String identifier which will be used within the “name” field of logging records generated within the “sqlalchemy.pool” logger. Defaults to a hexstring of the object’s id.
See also
Configuring Logging - further detail on how to configure logging.
pool_pre_ping¶ –
boolean, if True will enable the connection pool “pre-ping” feature that tests connections for liveness upon each checkout.
New in version 1.2.
See also
pool_size=5¶ – the number of connections to keep open inside the connection pool. This used with
QueuePoolas well asSingletonThreadPool. WithQueuePool, apool_sizesetting of 0 indicates no limit; to disable pooling, setpoolclasstoNullPoolinstead.pool_recycle=-1¶ –
this setting causes the pool to recycle connections after the given number of seconds has passed. It defaults to -1, or no timeout. For example, setting to 3600 means connections will be recycled after one hour. Note that MySQL in particular will disconnect automatically if no activity is detected on a connection for eight hours (although this is configurable with the MySQLDB connection itself and the server configuration as well).
See also
pool_reset_on_return='rollback'¶ –
set the
Pool.reset_on_returnparameter of the underlyingPoolobject, which can be set to the values"rollback","commit", orNone.See also
pool_timeout=30¶ –
number of seconds to wait before giving up on getting a connection from the pool. This is only used with
QueuePool. This can be a float but is subject to the limitations of Python time functions which may not be reliable in the tens of milliseconds.pool_use_lifo=False¶ –
use LIFO (last-in-first-out) when retrieving connections from
QueuePoolinstead of FIFO (first-in-first-out). Using LIFO, a server-side timeout scheme can reduce the number of connections used during non- peak periods of use. When planning for server-side timeouts, ensure that a recycle or pre-ping strategy is in use to gracefully handle stale connections.New in version 1.3.
plugins¶ –
string list of plugin names to load. See
CreateEnginePluginfor background.New in version 1.2.3.
query_cache_size¶ –
size of the cache used to cache the SQL string form of queries. Set to zero to disable caching.
The cache is pruned of its least recently used items when its size reaches N * 1.5. Defaults to 500, meaning the cache will always store at least 500 SQL statements when filled, and will grow up to 750 items at which point it is pruned back down to 500 by removing the 250 least recently used items.
Caching is accomplished on a per-statement basis by generating a cache key that represents the statement’s structure, then generating string SQL for the current dialect only if that key is not present in the cache. All statements support caching, however some features such as an INSERT with a large set of parameters will intentionally bypass the cache. SQL logging will indicate statistics for each statement whether or not it were pull from the cache.
Note
some ORM functions related to unit-of-work persistence as well as some attribute loading strategies will make use of individual per-mapper caches outside of the main cache.
See also
New in version 1.4.
use_insertmanyvalues¶ –
True by default, use the “insertmanyvalues” execution style for INSERT..RETURNING statements by default.
New in version 2.0.
- function sqlalchemy.engine_from_config(configuration: Dict[str, Any], prefix: str = 'sqlalchemy.', **kwargs: Any) Engine¶
Create a new Engine instance using a configuration dictionary.
The dictionary is typically produced from a config file.
The keys of interest to
engine_from_config()should be prefixed, e.g.sqlalchemy.url,sqlalchemy.echo, etc. The ‘prefix’ argument indicates the prefix to be searched for. Each matching key (after the prefix is stripped) is treated as though it were the corresponding keyword argument to acreate_engine()call.The only required key is (assuming the default prefix)
sqlalchemy.url, which provides the database URL.A select set of keyword arguments will be “coerced” to their expected type based on string values. The set of arguments is extensible per-dialect using the
engine_config_typesaccessor.- Parameters:
configuration¶ – A dictionary (typically produced from a config file, but this is not a requirement). Items whose keys start with the value of ‘prefix’ will have that prefix stripped, and will then be passed to
create_engine().prefix¶ – Prefix to match and then strip from keys in ‘configuration’.
kwargs¶ – Each keyword argument to
engine_from_config()itself overrides the corresponding item taken from the ‘configuration’ dictionary. Keyword arguments should not be prefixed.
- function sqlalchemy.create_mock_engine(url: str | URL, executor: Any, **kw: Any) MockConnection¶
Create a “mock” engine used for echoing DDL.
This is a utility function used for debugging or storing the output of DDL sequences as generated by
MetaData.create_all()and related methods.The function accepts a URL which is used only to determine the kind of dialect to be used, as well as an “executor” callable function which will receive a SQL expression object and parameters, which can then be echoed or otherwise printed. The executor’s return value is not handled, nor does the engine allow regular string statements to be invoked, and is therefore only useful for DDL that is sent to the database without receiving any results.
E.g.:
from sqlalchemy import create_mock_engine def dump(sql, *multiparams, **params): print(sql.compile(dialect=engine.dialect)) engine = create_mock_engine('postgresql+psycopg2://', dump) metadata.create_all(engine, checkfirst=False)
- Parameters:
url¶ – A string URL which typically needs to contain only the database backend name.
executor¶ – a callable which receives the arguments
sql,*multiparamsand**params. Thesqlparameter is typically an instance ofExecutableDDLElement, which can then be compiled into a string usingExecutableDDLElement.compile().
New in version 1.4: - the
create_mock_engine()function replaces the previous “mock” engine strategy used withcreate_engine().
- function sqlalchemy.engine.make_url(name_or_url: str | URL) URL¶
Given a string, produce a new URL instance.
The format of the URL generally follows RFC-1738, with some exceptions, including that underscores, and not dashes or periods, are accepted within the “scheme” portion.
If a
URLobject is passed, it is returned as is.See also
- function sqlalchemy.create_pool_from_url(url: str | URL, **kwargs: Any) Pool¶
Create a pool instance from the given url.
If
poolclassis not provided the pool class used is selected using the dialect specified in the URL.The arguments passed to
create_pool_from_url()are identical to the pool argument passed to thecreate_engine()function.New in version 2.0.10.
- class sqlalchemy.engine.URL¶
Represent the components of a URL used to connect to a database.
URLs are typically constructed from a fully formatted URL string, where the
make_url()function is used internally by thecreate_engine()function in order to parse the URL string into its individual components, which are then used to construct a newURLobject. When parsing from a formatted URL string, the parsing format generally follows RFC-1738, with some exceptions.A
URLobject may also be produced directly, either by using themake_url()function with a fully formed URL string, or by using theURL.create()constructor in order to construct aURLprogrammatically given individual fields. The resultingURLobject may be passed directly tocreate_engine()in place of a string argument, which will bypass the usage ofmake_url()within the engine’s creation process.Changed in version 1.4: The
URLobject is now an immutable object. To create a URL, use themake_url()orURL.create()function / method. To modify aURL, use methods likeURL.set()andURL.update_query_dict()to return a newURLobject with modifications. See notes for this change at The URL object is now immutable.See also
URLcontains the following attributes:URL.drivername: database backend and driver name, such aspostgresql+psycopg2URL.username: username stringURL.password: password stringURL.host: string hostnameURL.port: integer port numberURL.database: string database nameURL.query: an immutable mapping representing the query string. contains strings for keys and either strings or tuples of strings for values.
Members
create(), database, difference_update_query(), drivername, get_backend_name(), get_dialect(), get_driver_name(), host, normalized_query, password, port, query, render_as_string(), set(), translate_connect_args(), update_query_dict(), update_query_pairs(), update_query_string(), username
Class signature
class
sqlalchemy.engine.URL(builtins.tuple)-
classmethod
sqlalchemy.engine.URL.create(drivername: str, username: str | None = None, password: str | None = None, host: str | None = None, port: int | None = None, database: str | None = None, query: Mapping[str, Sequence[str] | str] = {}) URL¶ Create a new
URLobject.See also
- Parameters:
drivername¶ – the name of the database backend. This name will correspond to a module in sqlalchemy/databases or a third party plug-in.
username¶ – The user name.
password¶ –
database password. Is typically a string, but may also be an object that can be stringified with
str().Note
The password string should not be URL encoded when passed as an argument to
URL.create(); the string should contain the password characters exactly as they would be typed.Note
A password-producing object will be stringified only once per
Engineobject. For dynamic password generation per connect, see Generating dynamic authentication tokens.host¶ – The name of the host.
port¶ – The port number.
database¶ – The database name.
query¶ – A dictionary of string keys to string values to be passed to the dialect and/or the DBAPI upon connect. To specify non-string parameters to a Python DBAPI directly, use the
create_engine.connect_argsparameter tocreate_engine(). See alsoURL.normalized_queryfor a dictionary that is consistently string->list of string.
- Returns:
new
URLobject.
New in version 1.4: The
URLobject is now an immutable named tuple. In addition, thequerydictionary is also immutable. To create a URL, use themake_url()orURL.create()function/ method. To modify aURL, use theURL.set()andURL.update_query()methods.
-
attribute
sqlalchemy.engine.URL.database: str | None¶ database name
-
method
sqlalchemy.engine.URL.difference_update_query(names: Iterable[str]) URL¶ Remove the given names from the
URL.querydictionary, returning the newURL.E.g.:
url = url.difference_update_query(['foo', 'bar'])
Equivalent to using
URL.set()as follows:url = url.set( query={ key: url.query[key] for key in set(url.query).difference(['foo', 'bar']) } )
New in version 1.4.
-
attribute
sqlalchemy.engine.URL.drivername: str¶ database backend and driver name, such as
postgresql+psycopg2
-
method
sqlalchemy.engine.URL.get_backend_name() str¶ Return the backend name.
This is the name that corresponds to the database backend in use, and is the portion of the
URL.drivernamethat is to the left of the plus sign.
-
method
sqlalchemy.engine.URL.get_dialect(_is_async: bool = False) Type[Dialect]¶ Return the SQLAlchemy
Dialectclass corresponding to this URL’s driver name.
-
method
sqlalchemy.engine.URL.get_driver_name() str¶ Return the backend name.
This is the name that corresponds to the DBAPI driver in use, and is the portion of the
URL.drivernamethat is to the right of the plus sign.If the
URL.drivernamedoes not include a plus sign, then the defaultDialectfor thisURLis imported in order to get the driver name.
-
attribute
sqlalchemy.engine.URL.host: str | None¶ hostname or IP number. May also be a data source name for some drivers.
-
attribute
sqlalchemy.engine.URL.normalized_query¶ Return the
URL.querydictionary with values normalized into sequences.As the
URL.querydictionary may contain either string values or sequences of string values to differentiate between parameters that are specified multiple times in the query string, code that needs to handle multiple parameters generically will wish to use this attribute so that all parameters present are presented as sequences. Inspiration is from Python’surllib.parse.parse_qsfunction. E.g.:>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt") >>> url.query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': '/path/to/crt'}) >>> url.normalized_query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': ('/path/to/crt',)})
-
attribute
sqlalchemy.engine.URL.password: str | None¶ password, which is normally a string but may also be any object that has a
__str__()method.
-
attribute
sqlalchemy.engine.URL.port: int | None¶ integer port number
-
attribute
sqlalchemy.engine.URL.query: immutabledict[str, Tuple[str, ...] | str]¶ an immutable mapping representing the query string. contains strings for keys and either strings or tuples of strings for values, e.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt") >>> url.query immutabledict({'alt_host': ('host1', 'host2'), 'ssl_cipher': '/path/to/crt'}) To create a mutable copy of this mapping, use the ``dict`` constructor:: mutable_query_opts = dict(url.query)
See also
URL.normalized_query- normalizes all values into sequences for consistent processingMethods for altering the contents of
URL.query:
-
method
sqlalchemy.engine.URL.render_as_string(hide_password: bool = True) str¶ Render this
URLobject as a string.This method is used when the
__str__()or__repr__()methods are used. The method directly includes additional options.- Parameters:
hide_password¶ – Defaults to True. The password is not shown in the string unless this is set to False.
-
method
sqlalchemy.engine.URL.set(drivername: str | None = None, username: str | None = None, password: str | None = None, host: str | None = None, port: int | None = None, database: str | None = None, query: Mapping[str, Sequence[str] | str] | None = None) URL¶ return a new
URLobject with modifications.Values are used if they are non-None. To set a value to
Noneexplicitly, use theURL._replace()method adapted fromnamedtuple.- Parameters:
- Returns:
new
URLobject.
New in version 1.4.
See also
-
method
sqlalchemy.engine.URL.translate_connect_args(names: List[str] | None = None, **kw: Any) Dict[str, Any]¶ Translate url attributes into a dictionary of connection arguments.
Returns attributes of this url (host, database, username, password, port) as a plain dictionary. The attribute names are used as the keys by default. Unset or false attributes are omitted from the final dictionary.
-
method
sqlalchemy.engine.URL.update_query_dict(query_parameters: Mapping[str, str | List[str]], append: bool = False) URL¶ Return a new
URLobject with theURL.queryparameter dictionary updated by the given dictionary.The dictionary typically contains string keys and string values. In order to represent a query parameter that is expressed multiple times, pass a sequence of string values.
E.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_dict({"alt_host": ["host1", "host2"], "ssl_cipher": "/path/to/crt"}) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- Parameters:
query_parameters¶ – A dictionary with string keys and values that are either strings, or sequences of strings.
append¶ – if True, parameters in the existing query string will not be removed; new parameters will be in addition to those present. If left at its default of False, keys present in the given query parameters will replace those of the existing query string.
New in version 1.4.
-
method
sqlalchemy.engine.URL.update_query_pairs(key_value_pairs: Iterable[Tuple[str, str | List[str]]], append: bool = False) URL¶ Return a new
URLobject with theURL.queryparameter dictionary updated by the given sequence of key/value pairsE.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_pairs([("alt_host", "host1"), ("alt_host", "host2"), ("ssl_cipher", "/path/to/crt")]) >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- Parameters:
key_value_pairs¶ – A sequence of tuples containing two strings each.
append¶ – if True, parameters in the existing query string will not be removed; new parameters will be in addition to those present. If left at its default of False, keys present in the given query parameters will replace those of the existing query string.
New in version 1.4.
-
method
sqlalchemy.engine.URL.update_query_string(query_string: str, append: bool = False) URL¶ Return a new
URLobject with theURL.queryparameter dictionary updated by the given query string.E.g.:
>>> from sqlalchemy.engine import make_url >>> url = make_url("postgresql+psycopg2://user:pass@host/dbname") >>> url = url.update_query_string("alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt") >>> str(url) 'postgresql+psycopg2://user:pass@host/dbname?alt_host=host1&alt_host=host2&ssl_cipher=%2Fpath%2Fto%2Fcrt'
- Parameters:
query_string¶ – a URL escaped query string, not including the question mark.
append¶ – if True, parameters in the existing query string will not be removed; new parameters will be in addition to those present. If left at its default of False, keys present in the given query parameters will replace those of the existing query string.
New in version 1.4.
-
attribute
sqlalchemy.engine.URL.username: str | None¶ username string
Pooling¶
Engine は、connect() または execute() メソッドが呼び出されると、接続プールに接続を要求します。デフォルトの接続プールである QueuePool `は、必要に応じてデータベースへの接続を開きます。同時実行ステートメントが実行されると、`QueuePool は接続プールをデフォルトの5に増やし、デフォルトの”オーバーフロー”を10にします。 Engine は基本的に接続プールの”ホームベース”であるため、接続ごとに新しい Engine を作成するのではなく、アプリケーション内で確立されたデータベースごとに1つの Engine を保持する必要があります。
接続プーリングの詳細については、 Connection Pooling を参照してください。
Custom DBAPI connect() arguments / on-connect routines¶
特別な接続方法が必要な場合は、ほとんどの場合、このプロセスをカスタマイズするために create_engine() レベルでいくつかのフックのうちの1つを使用するのが最も適切です。
Special Keyword Arguments Passed to dbapi.connect()¶
すべてのPython DBAPIは、接続の基本を超えた追加の引数を受け入れます。共通パラメータには、文字セット・エンコード方式とタイムアウト値を指定するためのパラメータが含まれます。より複雑なデータには、特別なDBAPI定数とオブジェクト、およびSSLサブパラメータが含まれます。これらの引数を複雑にせずに渡すには、2つの基本的な方法があります。
Add Parameters to the URL Query string¶
単純な文字列値は、いくつかの数値やブーリアンフラグと同様に、URLのクエリ文字列で直接指定されることがよくあります。その一般的な例は、ほとんどのMySQL DB APIのように、文字エンコーディングの引数 encoding を受け入れるDB APIです:
engine = create_engine("mysql+pymysql://user:pass@host/test?charset=utf8mb4")クエリー・ストリングを使用する利点は、URLで指定されたDBAPIに移植可能な方法で、追加のDBAPIオプションを構成ファイルに指定できることです。このレベルで渡される特定のパラメーターは、SQLAlchemyダイアレクトによって変わります。すべての引数をストリングとして渡すダイアレクトもあれば、特定のデータ型を解析してパラメーターを別の場所(例えばドライバー・レベルのDSNや接続ストリングなど)に移動するダイアレクトもあります。この領域での方言ごとの振る舞いは現在さまざまであるため、特定のパラメーターがこのレベルでサポートされているかどうかを確認するには、使用中の特定の方言に関するダイアレクトのドキュメンテーションを調べる必要があります。
Tip
特定のURLに対してDBAPIに渡された正確な引数を表示する一般的なテクニックは、次のように Dialect. create_connect_args() メソッドを直接使用して実行できます:
>>> from sqlalchemy import create_engine
>>> engine = create_engine(
... "mysql+pymysql://some_user:some_pass@some_host/test?charset=utf8mb4"
... )
>>> args, kwargs = engine.dialect.create_connect_args(engine.url)
>>> args, kwargs
([], {'host': 'some_host', 'database': 'test', 'user': 'some_user', 'password': 'some_pass', 'charset': 'utf8mb4', 'client_flag': 2})The above args, kwargs pair is normally passed to the DBAPI as dbapi.connect(*args, **kwargs).
上記の args, kwargs の対は、通常 dbapi.connect(*args, **kwargs) としてDBAPIに渡されます。
Use the connect_args dictionary parameter¶
dbapi.connect() 関数にパラメータを渡すためのより一般的なシステムで、常にすべてのパラメータを渡すことが保証されているのは、 create_engine.connect_args ディクショナリパラメータです。これは、クエリ文字列に追加されたときにダイアレクトで処理されないパラメータに使用される場合や、特殊なサブ構造またはオブジェクトをDBAPIに渡す必要がある場合に使用されます。単に特定のフラグを True 記号として送信しなければならないだけの場合もありますが、SQLAlchemyダイアレクトはこのキーワード引数を認識せず、URLに表示される文字列形式から強制的に変換します。以下に、接続の基礎となる実装を置き換えるpsycopg2の”コネクションファクトリー”の使用方法を示します:
engine = create_engine(
"postgresql+psycopg2://user:pass@hostname/dbname",
connect_args={"connection_factory": MyConnectionFactory},
)もう1つの例は、pyodbcの”timeout”パラメータです:
engine = create_engine(
"mssql+pyodbc://user:pass@sqlsrvr?driver=ODBC+Driver+13+for+SQL+Server",
connect_args={"timeout": 30},
)上記の例は、URLの”query string”パラメータと create_engine.connect_args の両方が同時に使用できることも示しています。pyodbcの場合、”driver”キーワードはURL内で特別な意味を持ちます。
Controlling how parameters are passed to the DBAPI connect() function¶
connect() に渡されるパラメータを操作するだけでなく、 DialectEvents.do_connect() イベントフックを使用して、DBAPIの connect() 関数自体の呼び出し方法をさらにカスタマイズすることができます。このフックには、ダイアレクトが connect() に送信する完全な *args, **kwargs が渡されます。これらのコレクションは、使用方法を変更するために適切に変更できます:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
cparams["connection_factory"] = MyConnectionFactoryGenerating dynamic authentication tokens¶
DialectEvents.do_connect() は、 Engine の存続期間にわたって変化する可能性のある認証トークンを動的に挿入するための理想的な方法でもあります。例えば、トークンが get_authentication_token() によって生成され、 token パラメータでDBAPIに渡される場合、これは次のように実装できます:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user@hostname/dbname")
@event.listens_for(engine, "do_connect")
def provide_token(dialect, conn_rec, cargs, cparams):
cparams["token"] = get_authentication_token()See also
Connecting to databases with access tokens - SQL Serverに関するより具体的な例
Modifying the DBAPI connection after connect, or running commands after connect¶
SQLAlchemyが問題なく作成するDBAPI接続で、特殊なフラグの設定や特定のコマンドの実行など、実際に使用される前に完了した接続を変更したい場合は、 PoolEvents.connect() イベントフックが最も適切なフックです。このフックは、SQLAlchemyによって使用される前に、新しい接続が作成されるたびに呼び出されます:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "connect")
def connect(dbapi_connection, connection_record):
cursor_obj = dbapi_connection.cursor()
cursor_obj.execute("SET some session variables")
cursor_obj.close()Fully Replacing the DBAPI connect() function¶
最後に、 DialectEvents.do_connect() イベントフックを使用すると、接続を確立してそれを返すことによって、接続プロセス全体をテイクオーバーすることもできます:
from sqlalchemy import event
engine = create_engine("postgresql+psycopg2://user:pass@hostname/dbname")
@event.listens_for(engine, "do_connect")
def receive_do_connect(dialect, conn_rec, cargs, cparams):
# return the new DBAPI connection with whatever we'd like to
# do
return psycopg2.connect(*cargs, **cparams)DialectEvents.do_connect() フックは、以前の create_engine.creator フックよりも優先されます。これは引き続き使用可能です。 create_engine.creator() とは異なります。
Configuring Logging¶
Pythonの標準 logging モジュールは、SQLAlchemyの情報ログ出力とデバッグログ出力を実装するために使用されます。これにより、SQLAlchemyのログ出力を他のアプリケーションやライブラリと標準の方法で統合することができます。 create_engine() には create_engine.echo と create_engine.echo_pool という2つのパラメータがあり、ローカル開発の目的で sys.stdout への即時ログ出力を可能にします。これらのパラメータは、最終的には以下に説明する通常のPythonロガーと相互作用します。
このセクションは、上記のリンクされたログモジュールに精通していることを前提としています。SQLAlchemyによって実行されるすべてのログは、 logging.getLogger('SQLAlchemy') によって使用されるように、 SQLAlchemy 名前空間の下に存在します。ログが設定されている場合(つまり、 logging.basicConfig() などによって)、オンにできるSAロガーの一般的な名前空間は次のとおりです。
sqlalchemy.engine - SQLのエコーを制御します。SQL問い合わせの出力には`logging.INFO`を、問い合わせと結果セットの出力には
logging.DEBUGを設定します。これらの設定はそれぞれcreate_engine.echoのecho=Trueとecho="debug"と同じです。
sqlalchemy.pool- 接続プールのログ記録を制御します。接続の無効化とリサイクルイベントをログに記録するにはlogging. INFOに設定します。さらに、すべてのプールのチェックインとチェックアウトをログに記録するにはlogging. DEBUGに設定します。これらの設定は、それぞれcreate_engine.echo_poolのpool_echo=Trueとpool_echo="debug"と同じです。
sqlalchemy.dialects- SQLダイアレクトのカスタムロギングを制御します。ただし、ロギングが特定のダイアレクト内で使用される場合に限ります。これは一般的に最小限です。
sqlalchemy.orm- 様々なORM関数のロギングを、ORM内で使用される範囲で制御します。ORM内での使用は一般的に最小限です。マッパーの設定に関するトップレベルの情報を記録するには、logging.INFOに設定します。
例えば、 echo=True フラグの代わりにPythonのログ機能を使ってSQLクエリのログを取るには:
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)デフォルトでは、ログレベルは sqlalchemy 名前空間全体で logging.WARN に設定されているので、他の方法でログが有効になっているアプリケーション内であっても、ログ操作は行われません。
Note
SQLAlchemy Engine は、現在のログレベルが logging.INFO または logging.DEBUG として検出された場合にのみログ文を出力することで、Python関数呼び出しのオーバーヘッドを節約します。このレベルは、接続プールから新しい接続が取得されたときにのみチェックされます。したがって、すでに実行中のアプリケーションのログ設定を変更する場合、現在アクティブな Connection オブジェクト、またはより一般的にはトランザクション内でアクティブな Session オブジェクトは、新しい Connection が取得されるまで( Session の場合は、現在のトランザクションが終了して新しいトランザクションが開始された後)、新しい設定に従ってSQLをログに記録しません。
More on the Echo Flag¶
前述したように、 create_engine.echo と create_engine.echo_pool パラメータは、 sys.stdout への即時ロギングへのショートカットです:
>>> from sqlalchemy import create_engine, text
>>> e = create_engine("sqlite://", echo=True, echo_pool="debug")
>>> with e.connect() as conn:
... print(conn.scalar(text("select 'hi'")))
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Created new connection <sqlite3.Connection object at 0x7f287819ac60>
2020-10-24 12:54:57,701 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> checked out from pool
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine select 'hi'
2020-10-24 12:54:57,702 INFO sqlalchemy.engine.Engine ()
hi
2020-10-24 12:54:57,703 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> being returned to pool
2020-10-24 12:54:57,704 DEBUG sqlalchemy.pool.impl.SingletonThreadPool Connection <sqlite3.Connection object at 0x7f287819ac60> rollback-on-returnこれらのフラグの使用は、以下とほぼ同じです:
import logging
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)
logging.getLogger("sqlalchemy.pool").setLevel(logging.DEBUG)これらの2つのフラグは、既存のロギング設定とは 独立して 機能し、無条件に logging.basicConfig() を利用することに注意してください。これは、既存のロガー設定に 追加して 設定されるという効果があります。したがって、 ロギングを明示的に設定する場合は、ログ行の重複を避けるために、すべてのエコーフラグを常にFalseに設定してください 。
Setting the Logging Name¶
Engine や Pool などのインスタンスのロガー名は、デフォルトでは切り捨てられた16進の識別子文字列を使用します。これを特定の名前に設定するには、 create_engine.logging_name と create_engine.pool_logging_name を sqlalchemy.create_engine() と一緒に使用します。名前はロギング名 sqlalchemy.engine.Engine に追加されます:
>>> import logging
>>> from sqlalchemy import create_engine
>>> from sqlalchemy import text
>>> logging.basicConfig()
>>> logging.getLogger("sqlalchemy.engine.Engine.myengine").setLevel(logging.INFO)
>>> e = create_engine("sqlite://", logging_name="myengine")
>>> with e.connect() as conn:
... conn.execute(text("select 'hi'"))
2020-10-24 12:47:04,291 INFO sqlalchemy.engine.Engine.myengine select 'hi'
2020-10-24 12:47:04,292 INFO sqlalchemy.engine.Engine.myengine ()Tip
create_engine.logging_name および create_engine.pool_logging_name パラメータは、 create_engine.echo および create_engine.echo_pool と組み合わせて使用することもできます。ただし、エコーフラグがTrueに設定され、 ログ名がない 他のエンジンが作成された場合、避けられない二重ログ状態が発生します。これは、名前のないエンジンとログ名のあるエンジンの両方のメッセージをログに記録する sqlalchemy.engine.Engine のハンドラが自動的に追加されるためです。たとえば:
from sqlalchemy import create_engine, text
e1 = create_engine("sqlite://", echo=True, logging_name="myname")
with e1.begin() as conn:
conn.execute(text("SELECT 1"))
e2 = create_engine("sqlite://", echo=True)
with e2.begin() as conn:
conn.execute(text("SELECT 2"))
with e1.begin() as conn:
conn.execute(text("SELECT 3"))上記のシナリオでは、 SELECT 3 のログが2倍になります。これを解決するには、すべてのエンジンに logging_name が設定されていることを確認するか、 create_engine.echo と create_engine.echo_pool を使用せずに明示的にlogger/handlerを設定します。
Setting Per-Connection / Sub-Engine Tokens¶
New in version 1.4.0b2.
ロギング名は、寿命の長い Engine オブジェクトに設定するのに適していますが、ログメッセージ内の個々の接続やトランザクションを追跡する場合など、任意の大きな名前のリストに対応できるほど柔軟ではありません。
このユースケースでは、 Connection オブジェクトと Result オブジェクトによって生成されたログメッセージ自体が、トランザクション識別子やリクエスト識別子などの追加のトークンで補強されることがあります。 Connection.execution_options.logging_token パラメータは、接続ごとのtrackingtokenを確立するために使用される文字列引数を受け付けます:
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> with e.connect().execution_options(logging_token="track1") as conn:
... conn.execute(text("select 1")).all()
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:48:45,754 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:48:45,754 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:48:45,755 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)Connection.execution_options.logging_token パラメータは、 create_engine.execution_options または Engine.execution_options() を介してエンジンまたはサブエンジンに設定することもできます。これは、新しいエンジンを作成せずに、アプリケーションのさまざまなコンポーネントにさまざまなロギングトークンを適用する場合に便利です:
>>> from sqlalchemy import create_engine
>>> e = create_engine("sqlite://", echo="debug")
>>> e1 = e.execution_options(logging_token="track1")
>>> e2 = e.execution_options(logging_token="track2")
>>> with e1.connect() as conn:
... conn.execute(text("select 1")).all()
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] select 1
2021-02-03 11:51:08,960 INFO sqlalchemy.engine.Engine [track1] [raw sql] ()
2021-02-03 11:51:08,960 DEBUG sqlalchemy.engine.Engine [track1] Col ('1',)
2021-02-03 11:51:08,961 DEBUG sqlalchemy.engine.Engine [track1] Row (1,)
>>> with e2.connect() as conn:
... conn.execute(text("select 2")).all()
2021-02-03 11:52:05,518 INFO sqlalchemy.engine.Engine [track2] Select 1
2021-02-03 11:52:05,519 INFO sqlalchemy.engine.Engine [track2] [raw sql] ()
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Col ('1',)
2021-02-03 11:52:05,520 DEBUG sqlalchemy.engine.Engine [track2] Row (1,)Hiding Parameters¶
Engine が出力するログは、特定の文に存在するSQLパラメータの抜粋も示します。プライバシー保護のためにこれらのパラメータがログに記録されないようにするには、 create_engine.hide_parameters フラグを有効にします:
>>> e = create_engine("sqlite://", echo=True, hide_parameters=True)
>>> with e.connect() as conn:
... conn.execute(text("select :some_private_name"), {"some_private_name": "pii"})
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine select ?
2020-10-24 12:48:32,808 INFO sqlalchemy.engine.Engine [SQL parameters hidden due to hide_parameters=True]